
3TU.BSR: NIRICT's Response to Big Software on the Run
The goal of the highly innovative 3TU.BSR research program is to provide a solid scientific basis for in vivo software analytics while exploiting the world-renowned 3TU computer science groups working on process mining, visualization, software engineering, formal methods, security analysis, and distributed/large-scale computing. Due to his ground-breaking work on the workflow patterns, workflow verification, and process-aware information systems, Van der Aalst is widely recognized as the leading business process management researcher in the world. He was the first to see the value of process mining and developed various process discovery and conformance checking techniques. Van Deursen pioneered software engineering's first steps into automated testing of modern web applications. He also investigated the interplay between coding activities and developer testing activities. Van de Pol is a well-known expert on high-performance analysis of discrete systems and developed many parallel algorithms for state space generation, reduction, model checking, and cycle analysis. Next to these three representatives, many other NIRICT researchers are involved, e.g., Van Wijk working on visualization, Lagendijk working on statistical and information-theoretical methods for pattern recognition, Zaidman working on the analysis of software repositories, Huisman working on runtime conformance checking, and Katoen working on stochastic processes.
Within 3TU.BSR we have identified five tracks. These tracks cover the different areas where major breakthroughs are needed.
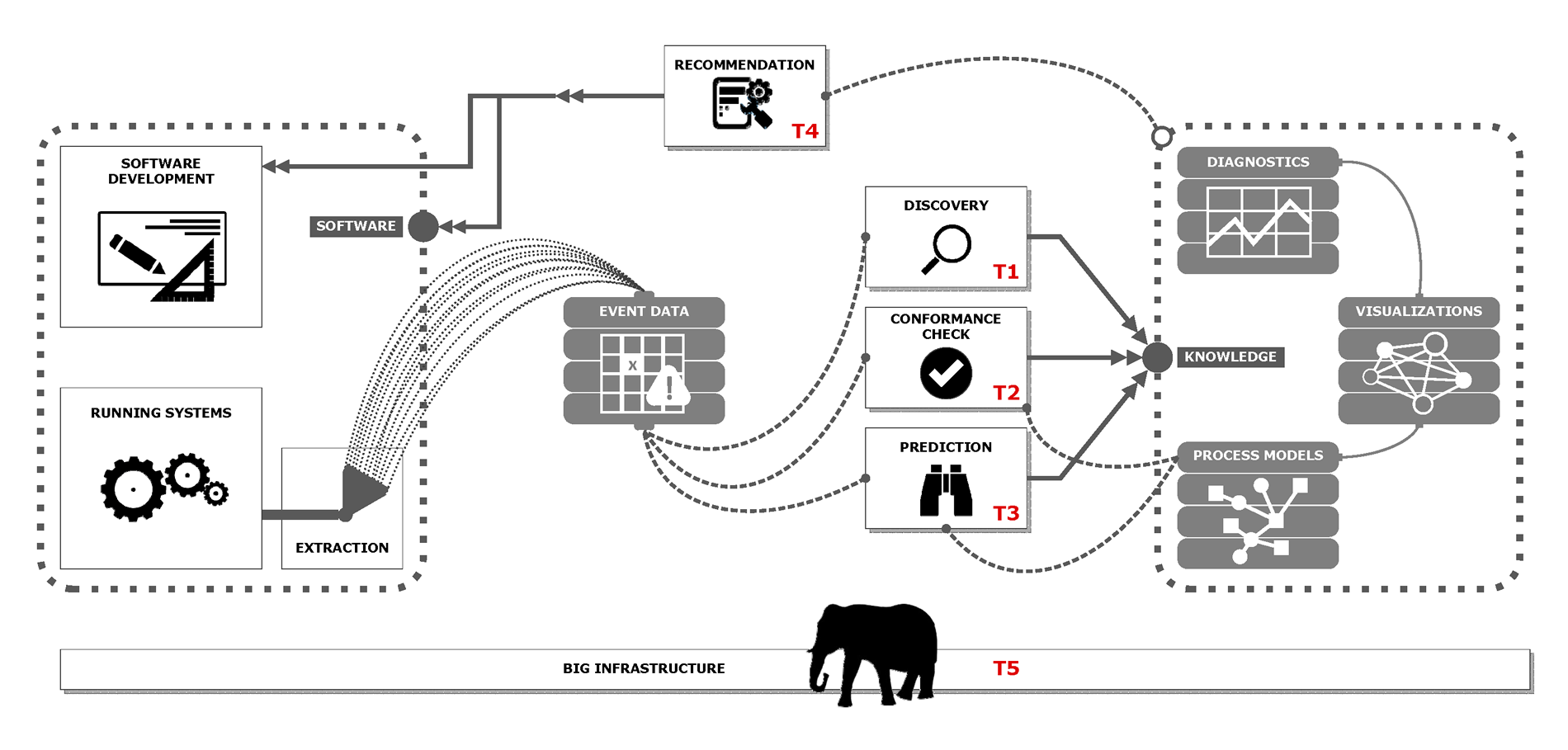
In the discovery track (Track T1) the primary focus is on creating more abstract representations of the massive amounts of event data. We will develop techniques for generating models and visualizations showing what is really going on in a software system or collection of systems. This analysis is of an explorative nature, i.e., there is no clear understanding of the problem. Based on the discovery track we will be able to determine relevant symptoms used in other tracks. In the conformance checking track (Track T2) we will develop techniques to detect deviations from some normative or descriptive model (possibly a model discovered in Track T1). The model may be based on domain knowledge or based on the symptoms identified in the discovery track. In the prediction track (Track T3) we will develop techniques to predict functional and non-functional properties of running cases, individual systems, and classes of systems. Whereas the discovery and conformance checking tracks (T1 and T2) only consider past behavior, this third track will aim to predict behavior (building on the results of T1 and T2). In the recommendation track (Track T4) we translate the results of the first three tracks (T1, T2, and T3) into recommendations related to the software system or the development process. Recommendations may provide input for testing, debugging, reuse, reconfiguration, and adaptation. In the big infrastructure track (Track T5) we focus on distributed and large-scale computing. The main goal of this track is to enable discovery, conformance checking, predictions, and recommendations at the unprecedented scale BSR aims at. This includes the extraction and storage of event data, privacy concerns, interoperability, and massive parallelization. The infrastructure should also be able to work in conjunction with modern technologies (clouds, grids, mobile devices, etc.).
We have identified six subtracks focusing on the most pressing challenges in T1-T5. We also identified common case studies (e.g., the Open Source Eclipse Ecosystem) to ensure collaboration between all subtracks.
